
发布者:大恒图像 发布时间:2018-07-09 分享:
一、 准备样本
我们以药片缺陷检测为例,假设样品可以分为三类,正常(Normal)、破损(Crack)以及脏污(Contamination)。我们需要根据样本类别名称创建3个文件夹,并将分割好的样本分别放置到相应文件夹中。
二、 修改例程
1、 打开例程
打开HALCON的集成开发环境HDevelop,在“文件”菜单中单击“示例程序”并选择“深度学习”中的第一个例程。

如果环境配置成功,例程是可以直接运行的,感兴趣的朋友也可以先浏览一下例程的运行效果。
2、 备份例程
将例程另存为到样本数据文件夹同级目录

3、修改路径
1) 修改样本路径为pilltest文件夹,并填充对应的子文件夹名称(类别名称)
2) 修改预处理图像保存路径为pill_preprocessed(可随意命名)
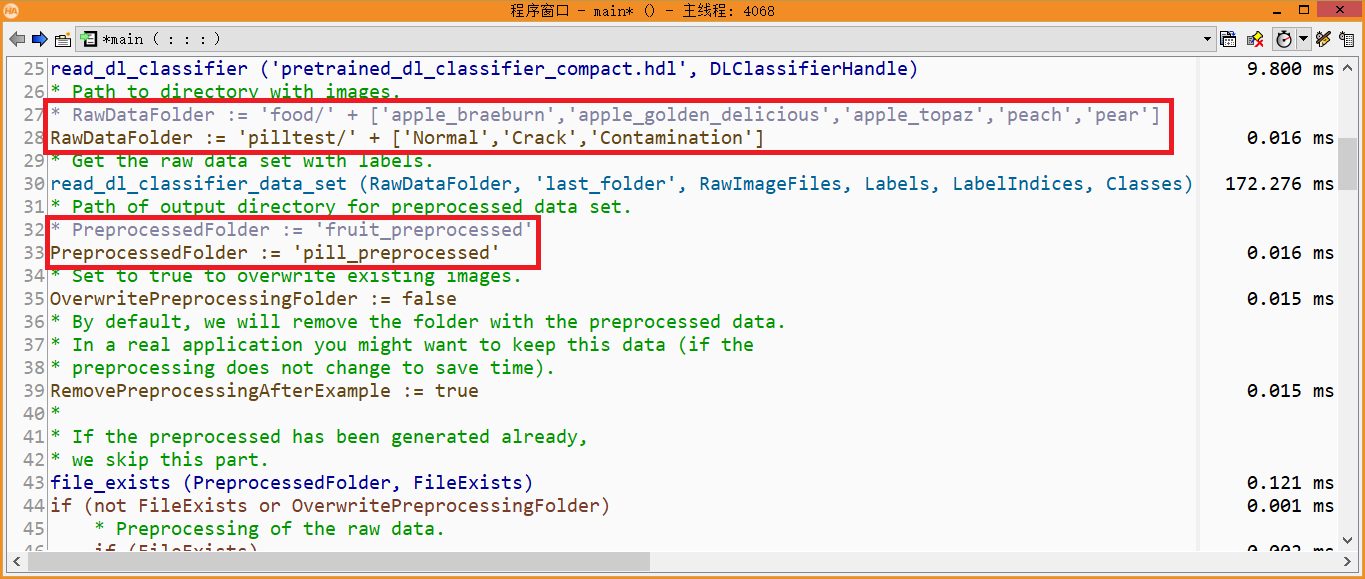
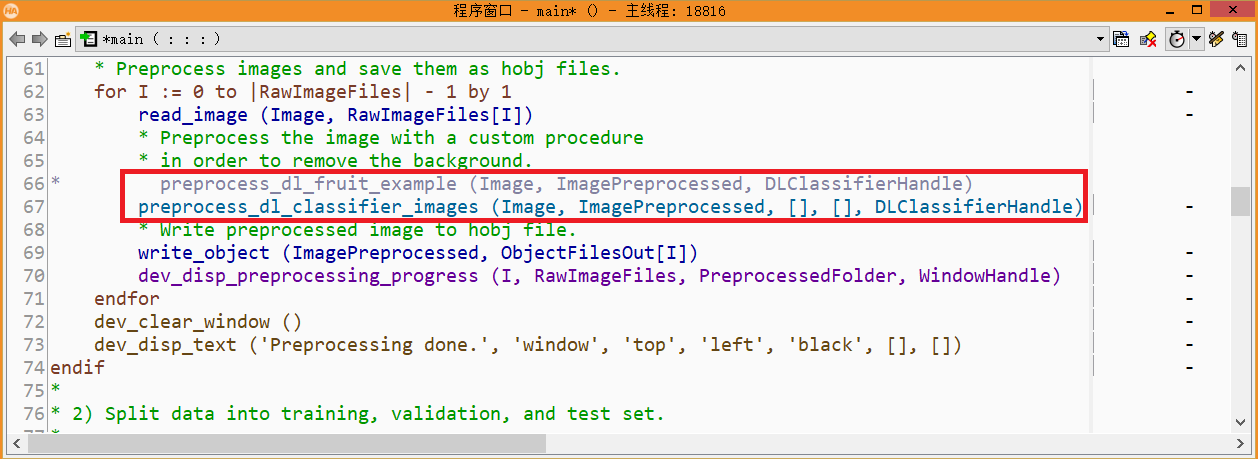
4、 修改图像预处理函数
1) 训练图像预处理
2) 分类图像预处理
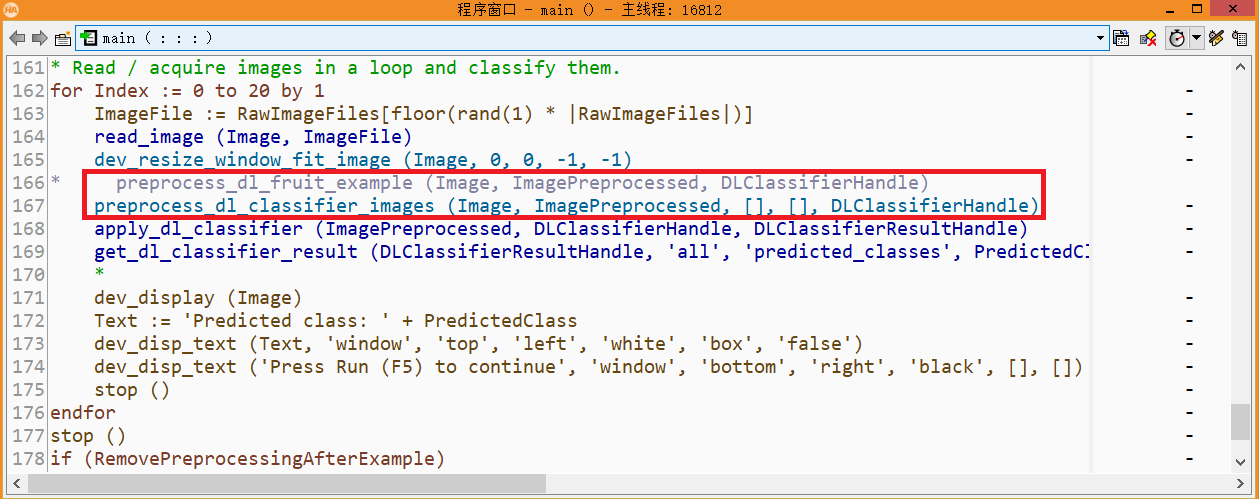
三、 训练测试网络
1、 执行训练
点击“执行”按钮,会出现一些水果的图像,不用理会他们,毕竟我们改的是人家的例程,为了快捷起见我们并没有注释旧的样本展示代码。

继续点击“执行”会出现训练曲线图。如果在此期间弹出显存不足的错误,请大家适当调整单批样本的训练数目
显存不足错误信息

训练的时间跟你的样本数目和电脑配置有关,我们以NVIDIA 1050的显卡、i7CPU为例,如果你的样本在2000以内,一般20分钟左右就可以训练完毕。如果你的样本比较大,比如8000以上,那你可以先去睡一觉了,4小时以后再回来。图中横坐标为训练代数,纵坐标为训练误差。下面奉上小编的训练结果。
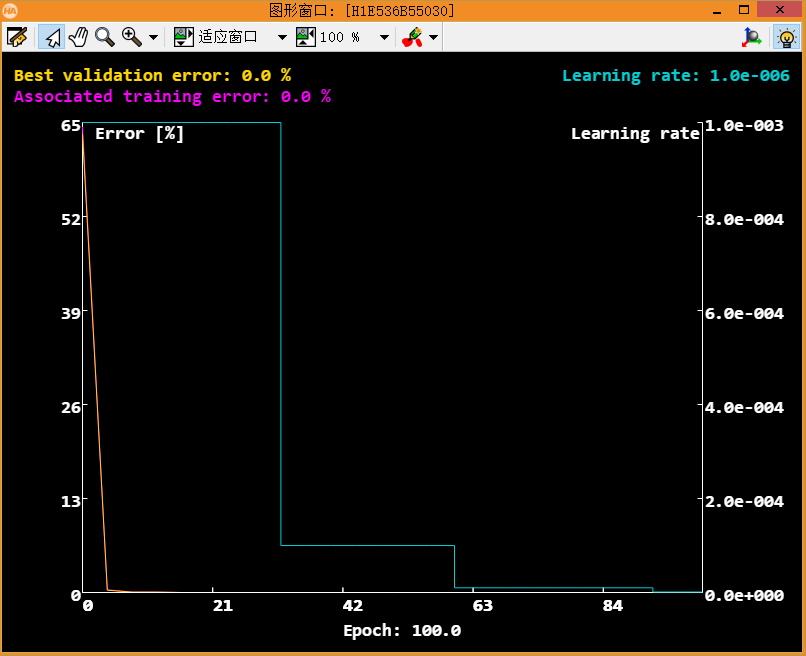
上图为从第0代得到第100带的训练曲线,我们可以看到最终训练和校验误差均为0。再来看看混淆矩阵,除了主对角线上其他位置也都是0。如果你也获得了跟我同样的处理结果,那么恭喜你(^_^),你的分类器已经可以正常运作了。
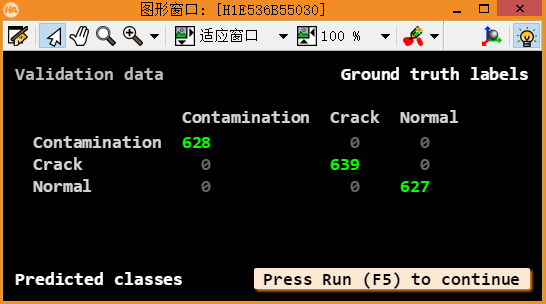
分类器训练好后就到了我们享用劳动成果的时候,继续点击“执行”或者“F5”就可以看到处理结果。
处理结果

关于深度学习技术的介绍及应用我们就先聊到这里。希望本文能够让大家对深度学习有一个初步的认识,并能够快速的搭建自己的深度学习网络。
以上内容为大恒图像原创文章,如转载请注明出处。
地址:北京市海淀区苏州街3号大恒科技大厦北座12层
邮箱:sales@daheng-imaging.com
